Definite Loops with for
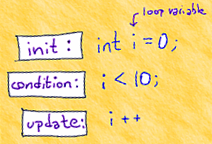
C++ has a loop designed for repeating an operation a fixed number of times: the for loop. You already met the range-based for loop in the last section. In this section we'll cover the traditional classic counter-controlled version.
The pattern used when you simply want to repeat an action n times is this:
times <- times to repeat
i <- 0
While i is less than times
Do action
i <- i + 1Here is this pattern translated into C++ using the for loop.
int times = 5; // repeat 5 times;
for (int i = 0; i < times; ++i)
{
cout << "Hello" << endl;
}The traditional for loop has three sections inside its parentheses:
- The initialization expression is evaluated once before the loop is entered. It creates and initializes the loop control variable, often named i. You may create other variables of the same type in this section. These variables have statement scope; they are not available after the loop body. The initialization section ends with a semicolon.
- The test condition is first evaluated after the initialization. If true, the body is entered; if false, it is skipped. The condition also ends in a semicolon.
- The update expression is evaluated after the loop body is completed. It does not end in a semicolon. The update expression must change one of the variables in the condition, which is evaluated again, immediately following the update.
Often, the index or loop control variable is not used inside the body of the loop; it simply controls the number of repetitions. Single letter names such as i and j are conventional. If you want others to understand your code, you'll conform to this convention.
The loop shown here goes from 0 to less-than times, so we say that this loop uses asymmetric bounds. This means the lower bounds is included while the upper bound is excluded.
Sequences & Symmetric Bounds
A second idiomatic variation of the for loop is used to generate sequential data, such as counting from start to finish:
for (int var = start; var < finish; update-var)...In this for loop the actions in the body are executed with the variable var set to each value between start and finish, inclusive.
Because we include both ends, we say that the bounds used in this loop are symmetric. Use this loop to count from 1 to 100 like this:
for (int i = 1; i <= 100; ++i)Here's another example. In this pattern, the loop variable is used to produce a sequence of data.
int factorial(int n)
{
int result = 1;
for (int i = 1; i <= n; ++i) {
result *= i;
}
return result;
}As you can see, this example uses the loop to implement the factorial function, the product of the integers between 1 and n. The for loop variable i goes from 1 to n (inclusive). The body of the loop updates result by multiplying it by i.
Counting Down
As the factorial example shows, the update update expression need only
move the loop variable closer to the loop bounds. It must
advance the loop; it doesn't need to increment. Here's and example:
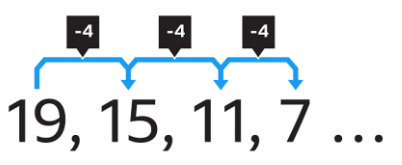
Here we want to start the loop at a large number, and decrease the index by four on each iteration. In other words, we want to count down rather than counting up. Here's what this looks like in code:
for (int i = 19; i >= 0; i -= 4)
cout << i << " ";
cout << endl;New software update available. Don't use conditions like i != 0, unless you are certain that the condition will be met. Because we are decrementing by four, we will never set i to 0 and so we would have an infinite or endless loop.
Processing Strings
One use of the for loop is to process strings. The for loop, and the asymmetric bounds pattern are ideal, because the subscripts use by strings and arrays all begin at 0, and the last element is always found at size() – 1.
The canonical classic for loop to process every character in a string, should look something like this:
for (size_t i = 0, len = str.size(); i < len; ++i)
{
char c = str.at(i); // now, process c in some way
}Note that the string::size() member function returns an unsigned type. If you are not careful, that can lead to unexpected results like this:
for (size_t len = str.size() - 1; i >= 0; --i) ...
This loop intended to count down from the last character to the first at index 0. However, if str is an empty string, then i starts at the largest possible unsigned number, instead of -1, since unsigned numbers "wrap around". Even worse, because i is an unsigned type, the condition i >= 0 can never be false, so you can never exit the loop.
Here is a loop that is written correctly:
for (size_t i = str.size(); i > 0; --i)
{
char c = str.at(i - 1);
}Alternatively, you can store str.size() in an int variable, as long as you:
-
cast the returned value from str.size() to an int
like this:
for (int i = static_cast<int>(str.size()); i >= 0; --i) ... - make sure that the string you are processing is no longer than the positive range of an int. If you do this, your loop will not work if you have a large string.
You may see the idiomatic loop written like this:
for (size_t i = 0; i < str.size(); ++i)
// do something with str[i] or str.at(i)This is a bad habit which assumes that calling size() is "free"—that is, it executes in constant time and there is no overhead for calling the function. This is close to true for string::size(), but it is not true for all functions. For instance, when working with C-style strings, using the equivalent strlen() function is very expensive. Don't train your fingers to do that.
Even worse is combining this bad habit with int indexes, like this:
for (int i = 0; i < str.size(); ++i)...The comparison i < str.size() automatically converts the type of i to an unsigned size_t. If i ever becomes negative, it is compared as if it were a very large positive number. Your compiler may warn you if you mix signed and unsigned numbers like this, but it's easier to remember: Just don't do it!
Since size() never changes in the loop, store the length in a variable, and use the variable in your test. Here is an example:
for (size_t i = 0, len = str.size(); i < len; ++i)...Should you use i++ or ++i in your loop update expression? With int or size_t indexes, it makes to difference. The effect is the same either way. However, I prefer the prefix version (++i) because I want to "train my fingers" for more the more advanced iterator loops you'll work with in CS 250. With iterators, often the i++ version is much slower, or even non-existent.
Hands On: Counting Vowels
Now it's your turn. On the next page you'll find a function which should count the number of lower-case vowels in its string parameter.
Watch the solution video
Look at the hints I've supplied here, and give it a try.
- I have already written a portion of the function skeleton (or stub) for you. Since the function returns an int, you just need to create the result variable, initialize it to zero, and return it at the end of the function.
- Next, use the canonical classic for loop (from the previous page) to process and retrieve every character in the string. You should memorize this pattern so that it is always at your fingertips when required.
- Finally, check the character to see if it is one of aeiou. If it is, then count it.
After you've given it a try, come back here and watch the solution video.
Hands On: Counting Substrings
Processing substrings requires a little more work than processing individual characters. On the next page you'll find a function, countSubs(), which counts the number of times that one string, s2, appears inside another, s1.
Watch the solution video
Complete the stub by adding a variable to hold the count, and then return it. Your code should now compile and run. You might even get a few correct.
int countSubs(const string& s1, const string& s2)
{
int count{0};
. . .
return count;
}Next, to extract a substringfrom str, you use the code:
string subs = s1.substr(index, count);The variable index is the position you want to start extracting from, and count is the number of characters to extract. Compare the substring to s2, and, if it matches, count it.
if (subs == s2) { ++count; }Go ahead and complete the exercise on the next page, and then come back here and check your work with the solution below.
More Efficient Substrings
Here's an illustration of the loop we just wrote, using it to count the number of times that moo appears in moon.
Watch the video
You'll notice that the last two iterations of the loop are not necessary, since we're comparing moo to on, and then a last time to n.
You may have encountered this situation in Java, where you'd solve it by changing the loop like this:
for (size_t i = 0, len = s1.size() - (s2.size() - 1); i < len; ++i)Now, your code correctly works for the example shown here, only completing the first two repetitions, and skipping the two extraneous ones at the end.
However, what if the string s1 contained m instead of
moon. In Java, the expression
s1.size() - (s2.size() - 1) would result in
a negative number (1 - (3 - 1)->-1), and the loop would work
correctly. In C++, that's not the case, since the types are unsigned numbers, so the result "wraps around" to a very large number, and your program
crashes.
That means, to get this to work correctly for any input in C++, you need to add a loop guard like this:
size_t len1 = s1.size(), len2 = s2.size();
if (len2 <= len1{)
for (size_t i = 0, len = len1 - (len2 - 1); i < len; ++i{)
if (s1.substr(i, len2) == s2){ count++;}
}
}Substrings Redux
Instead of using a loop guard, let's think about the loop in a different way. You need to loop through s1, extracting each substring, and comparing it to s2. Rather than writing a for loop with index refer to the beginning of the substring, you can have it point to the element following the substring, and then extract the characters preceding index.
Watch the video
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| c | a | t | a | p | u | l | t | |
| ↑ | ↑ | |||||||
A picture might help. Suppose s1 is "catapult" and s2 is "tap", here is how that looks. Your loop becomes very easy to write, and you don't need any extra if statements:
int count{0}; // times s2 found in s1
size_t slen{s2.size()}; // size of string looking for
for (size_t i = slen, len= s1.size(); i <= len; ++i )
{
string subs = s1.substr(i - slen, slen );
if (subs == s2) { ++count; }
}
return count;Things to notice about this loop:
- The loop index (i) starts at slen, where slen is the size of the substring you intend to extract. It does not start at 0.
- When calling substr(index, count), the index is i-slen, which means you are extracting the characters before i, not after it.
- Since i points to the first position past your substring, the loop condition is not i < len, but i <= len. (Make sure you don’t confuse len and slen).
All that’s left to do is to compare subs to s2 and update your counter. With C++ strings, you can use ==; you don’t need to use an equals() method as you would in Java.